ASCO Annual Meeting 2026 · 会议观察
ASCO 2026 的 AI:从研究主题到工具
ASCO 2026 议程的 8,025 篇发表里,挂上「Artificial Intelligence」标签的有 220 篇——单一最大的次分类。这些 AI 大多不是新模型,而是被用在具体的差事上:从记录做预测、读影像、把病摘结构化,以及为患者匹配试验。

/ scale /
AI 在议程中有多少、摆在哪
在阅读任何一篇摘要之前,先看数字。在 ASCO 2026 公开议程所收录的 8,025 篇发表中,有 220 篇挂上「Artificial Intelligence」次分类标签——单一最大的次分类,领先任何个别的疾病部位或药物类别次分类。算得更宽一点,有 1,039 篇(13%)在文内某处提及 AI 方法。这个数字反映的是 ASCO 如何标记摘要,而非把每一种方法逐一对打点算的结果。
这 220 篇 AI 次分类摘要中,有 136 篇(62%)被列为「Publication Only」——纳入线上会议录,而非给海报或口头时段。在更广的 1,039 篇里,比例相近:527 篇(51%)是 Publication Only。议程里很大一部分的 AI,是以书面会议录的形式存在,在线上被阅读,而非从台上报告。
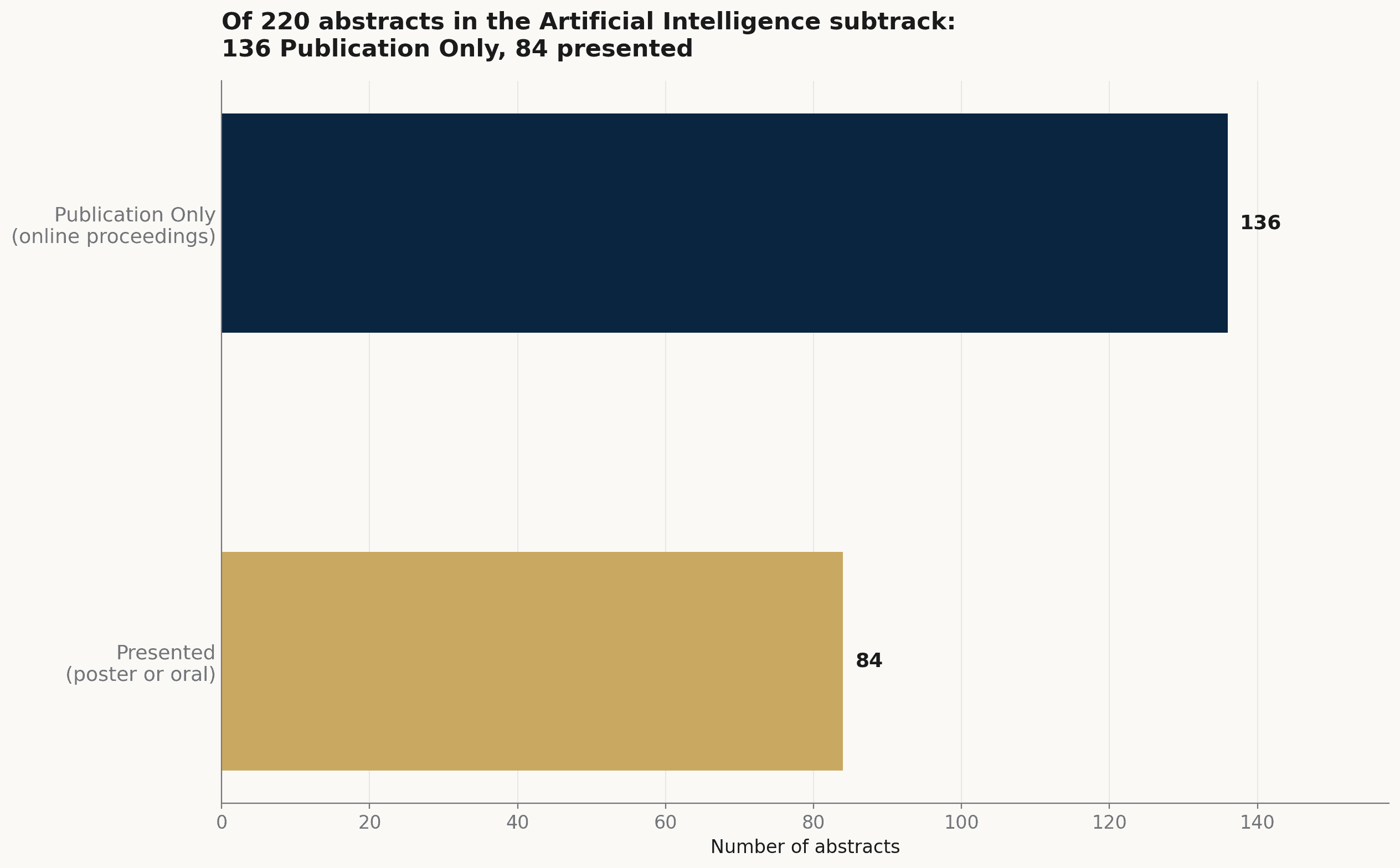
Artificial Intelligence 次分类的 220 篇摘要,依进入议程的方式区分:136 篇为 Publication Only,84 篇有海报或口头报告。
数据来源:ASCO 2026 公开议程 · AAI 分析
比例本身就是重点。一个方法填满了单一最大的次分类,而且多半以被接受的会议录、而非口头报告的形式出现——这看起来不太像一个抢版面的主题,而更像在研究被记录的方式里可能已成常规的一环。
/ uses /
AI 被用来做什么
若按任务来读,议程里的 AI 聚集在几件实务差事上,而非单一主导的应用。(一篇摘要可能同时落在不只一类,因此各群会重叠。)
在取用真实世界数据的 AI 篇章中,最大的一群是用常规记录做结果与风险预测(152 篇)。紧接在后的是读影像与病理(116 篇),以及把非结构化记录——病摘、病历、电子病历——转成结构化字段(114 篇)。试验匹配与入组资格筛选(61 篇)、治疗选择与决策支持(55 篇),以及不良反应检测(43 篇)随后。其中一篇以大型语言模型(LLM)直接从病历标记免疫相关不良反应(Abstract 12133);另一篇在一个 phase II 试验里嵌入 NLP chatbot,以风险算法为患者自述症状分级(Abstract 12132)。
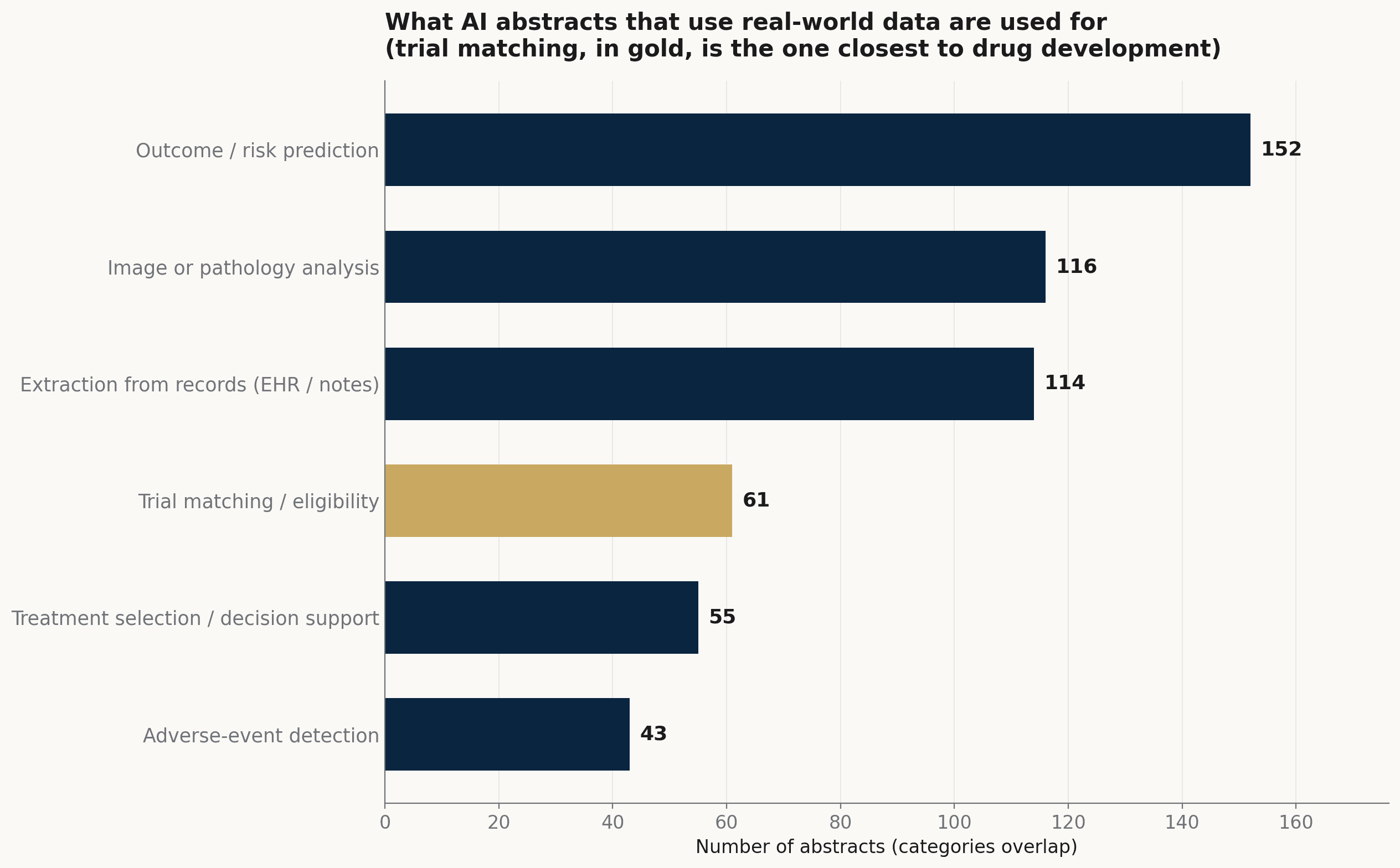
取用真实世界数据的 AI 摘要被用来做什么。预测、影像与记录提取是最大的几件差事;试验匹配则是最贴近试验如何被建立的一块。类别可重叠。
数据来源:ASCO 2026 公开议程 · AAI 关键词分析(类别可重叠)
喂养这些任务的数据,越来越是真实世界、而非来自试验:临床记录、registry 与理赔数据出现在全议程的 2,157 篇(27%)。当一篇 AI 摘要同时取用真实世界数据,这些记录就是模型所读、所预测、所筛选的原料——不过共用一个关键词标签,只是两者实际接得多紧的粗略代理。约三分之一的 AI 摘要(1,039 篇中的 339 篇,33%)也提到外部或前瞻性验证的步骤,这大致反映出有多少把工具拿到构建数据以外去测试。
/ trial-matching /
试验匹配:AI 最贴近试验如何被建立的一块
在这些实务差事里,试验匹配最贴近药物开发。它是用 AI 来判断哪些患者符合哪些试验的资格,并从一家诊所自己的患者群里主动捞出候选者,而不是等他们被转介进来。它也是议程中方法学描述最详细的一块,值得把整条管线走一遍。
这类工具共用一套大致相同的概念架构,通常三步。第一步,把试验的入组条件——为人类读者写成散文的 inclusion 与 exclusion——解析成可运算的规则:像「measurable disease、ECOG 0–1、无 prior anti–PD-1、EGFR exon 19 deletion」这样一句(仅为示意),被拆成一组结构化、可查询的条件(忠实的编码还得厘清是哪一版 RECIST、哪一种 assay、第几线治疗)。第二步,从记录组出患者 profile——结构化字段,再加上非结构化的病摘、病理与基因报告。其中一部分是用自然语言处理自动提取;一部分仍是由人用病历自由文字搜索工具(如 NCI 支持的 EMERSE)把相关段落捞出来。第三步,一个匹配引擎拿两者互比——传统上是在结构化字段上跑规则逻辑,再叠上 NLP 与 ontology 映射。有些较新的系统用大型语言模型逐条裁定条件、回传附逐条理由的排序候选名单,但这是新兴做法、还不是常态,而且其输出是供人复核,而非自主决定。
这些工具怎么被测试,和它们怎么运作一样重要,而议程对此讲得很明白。Abstract 1501 是最清楚的一例:在一家 community–academic 混合型癌症中心做的回溯性研究,把一套 AI 集中式筛选系统,拿来和它可能辅助的人工 pre-screening 相比,并由专家或人工裁定匹配结果。它的 framing 很直接——入组不足,部分是因为 pre-screening 依赖人工,而一套 AI 筛选「需要稳健的验证才能促成信任与采用」。它的终点是与那份人工判断在既有记录上的一致性;它说的是可行性与信任,而不是是否真的有更多患者被收进试验。
真正难的,与其说是匹配逻辑,不如说是背后的数据。条件常常取决于记录并未以结构化形式持有的事实——一个还没被开立的分子检测、一段埋在叙事里的前线治疗史、一个「28 天内」的时间窗、一条只存在于自由文字里的「无活动性自身免疫疾病」排除条件。否定语、时序与治疗线数的排序、缺漏或尚未做的检测,以及各中心不一的病历书写习惯,都是自动化入组判断常出错的地方——在一家中心验证过的工具,未必能搬到下一家。而议程目前还没能呈现这些工具能在规模上提高入组的前瞻性证据;多数报告,包括 1501,都停在可行性与一致性。方向已定,结果数据还在前头。
/ new-subtrack /
议程把这类工作放在哪,以及前沿技术
2026 年,议程新增一个次分类,名为 Clinical Informatics / Artificial Intelligence / Data Science,把先前分散在各疾病与方法轨道上的运算与数据工作收拢起来。它收了 83 篇摘要。
在更广的议程里,最新的技术仍是薄薄一层。大型语言模型或具名的 GPT 系统出现在 115 篇,foundation model 在 22 篇,digital twin 在 5 篇。这些是名义上的前沿;在数量上,对照 8,025 篇发表,仍然很小。
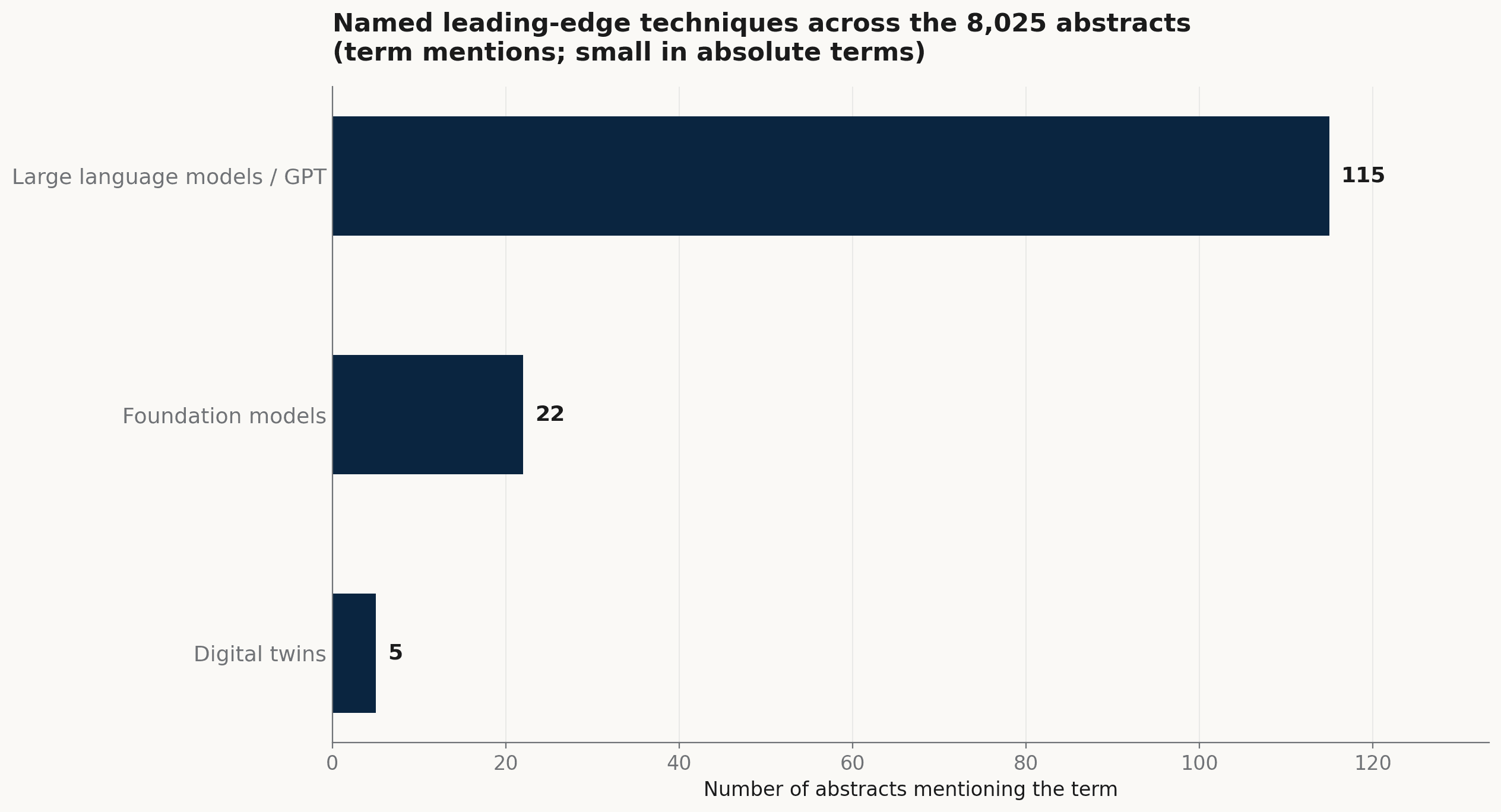
8,025 篇摘要中,具名的前沿技术。大型语言模型以提及次数领先;foundation model 与 digital twin 在绝对数量上仍小。
数据来源:ASCO 2026 公开议程 · AAI 关键词分析(术语提及)
新增一个次分类是一个前瞻信号。当议程委员会判断某一类工作已成形到足以单独追踪时,才会把它收进同一个标题之下——这通常标示出组织者预期之后会有更多。它本身对科学说得不多;它说的是议程在哪里腾出了位置。
/ takeaway /
方向,以及我们的位置
从议程可读出两个方向,都谨慎看待。其一,AI 正从研究的「主题」,转向完成任务的「手段」:多数 AI 摘要现在报告的是一件被完成的差事——做了一个预测、读了一份记录、匹配了一个患者——而不是为了方法本身而引入一个方法。
其二,最贴近操作的那些任务——试验匹配、入组资格筛选、site 选择——是 AI 最可能直接接上试验运作方式的地方。那里的证据目前还停在可行性层级,而非前瞻性结果,所以这是一个值得观察的方向,而非已成定论的结果。
这正是 Apex AI Institute 药物开发这条线工作的地方。Pillar 1 为早期肿瘤学试验开发并评估 AI 方法——site 与 investigator 选择、试验匹配,以及 biomarker 分析。ASCO 议程正忙于同样这些任务,是背景脉络,而不是对任何单一工具(包括我们自己的)的验证。我们会在后续的 briefing 里报告我们自己的系统,并明白交代它们的验证状态,使用与本篇相同的模板。