ASCO Annual Meeting 2026 · 會議報導
ASCO 2026 的 AI:從研究主題到工具
ASCO 2026 議程的 8,025 篇發表裡,掛上「Artificial Intelligence」標籤的有 220 篇——單一最大的次分類。這些 AI 大多不是新模型,而是被用在具體的差事上:從紀錄做預測、讀影像、把病摘結構化,以及為病人配對試驗。

/ scale /
AI 在議程中有多少、擺在哪
在閱讀任何一篇摘要之前,先看數字。在 ASCO 2026 公開議程所收錄的 8,025 篇發表中,有 220 篇掛上「Artificial Intelligence」次分類標籤——單一最大的次分類,領先任何個別的疾病部位或藥物類別次分類。算得更寬一點,有 1,039 篇(13%)在文內某處提及 AI 方法。這個數字反映的是 ASCO 如何標記摘要,而非把每一種方法逐一對打點算的結果。
這 220 篇 AI 次分類摘要中,有 136 篇(62%)被列為「Publication Only」——納入線上會議錄,而非給海報或口頭時段。在更廣的 1,039 篇裡,比例相近:527 篇(51%)是 Publication Only。議程裡很大一部分的 AI,是以書面會議錄的形式存在,在線上被閱讀,而非從台上報告。
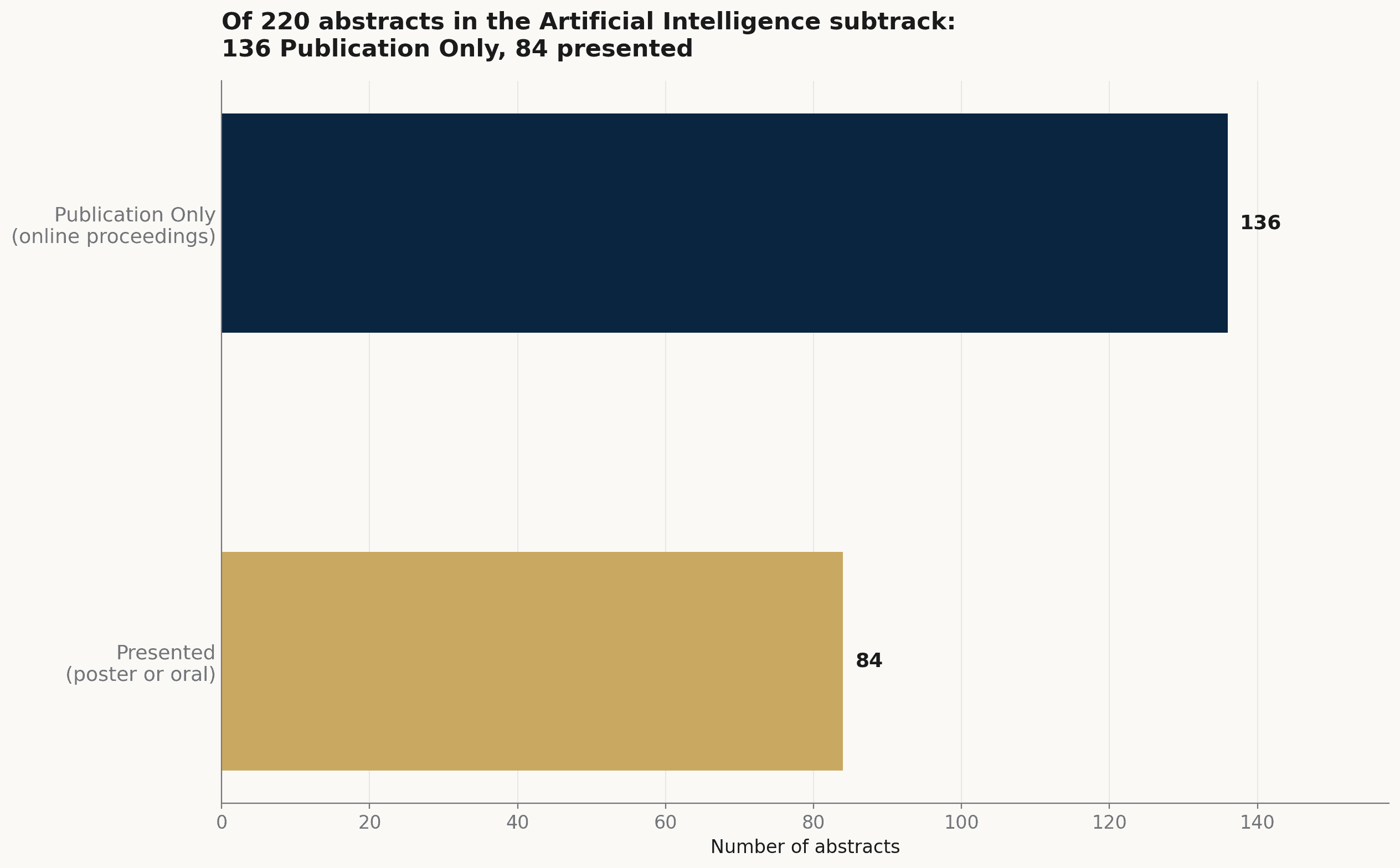
Artificial Intelligence 次分類的 220 篇摘要,依進入議程的方式區分:136 篇為 Publication Only,84 篇有海報或口頭報告。
資料來源:ASCO 2026 公開議程 · AAI 分析
比例本身就是重點。一個方法填滿了單一最大的次分類,而且多半以被接受的會議錄、而非口頭報告的形式出現——這看起來不太像一個搶版面的主題,而更像在研究被記錄的方式裡可能已成常規的一環。
/ uses /
AI 被用來做什麼
若按任務來讀,議程裡的 AI 聚集在幾件實務差事上,而非單一主導的應用。(一篇摘要可能同時落在不只一類,因此各群會重疊。)
在取用真實世界資料的 AI 篇章中,最大的一群是用常規紀錄做結果與風險預測(152 篇)。緊接在後的是讀影像與病理(116 篇),以及把非結構化紀錄——病摘、病歷、電子病歷——轉成結構化欄位(114 篇)。試驗配對與適格篩選(61 篇)、治療選擇與決策支援(55 篇),以及不良反應偵測(43 篇)隨後。其中一篇以大型語言模型(LLM)直接從病歷標記免疫相關不良反應(Abstract 12133);另一篇在一個 phase II 試驗裡嵌入 NLP chatbot,以風險演算法為病人自述症狀分級(Abstract 12132)。
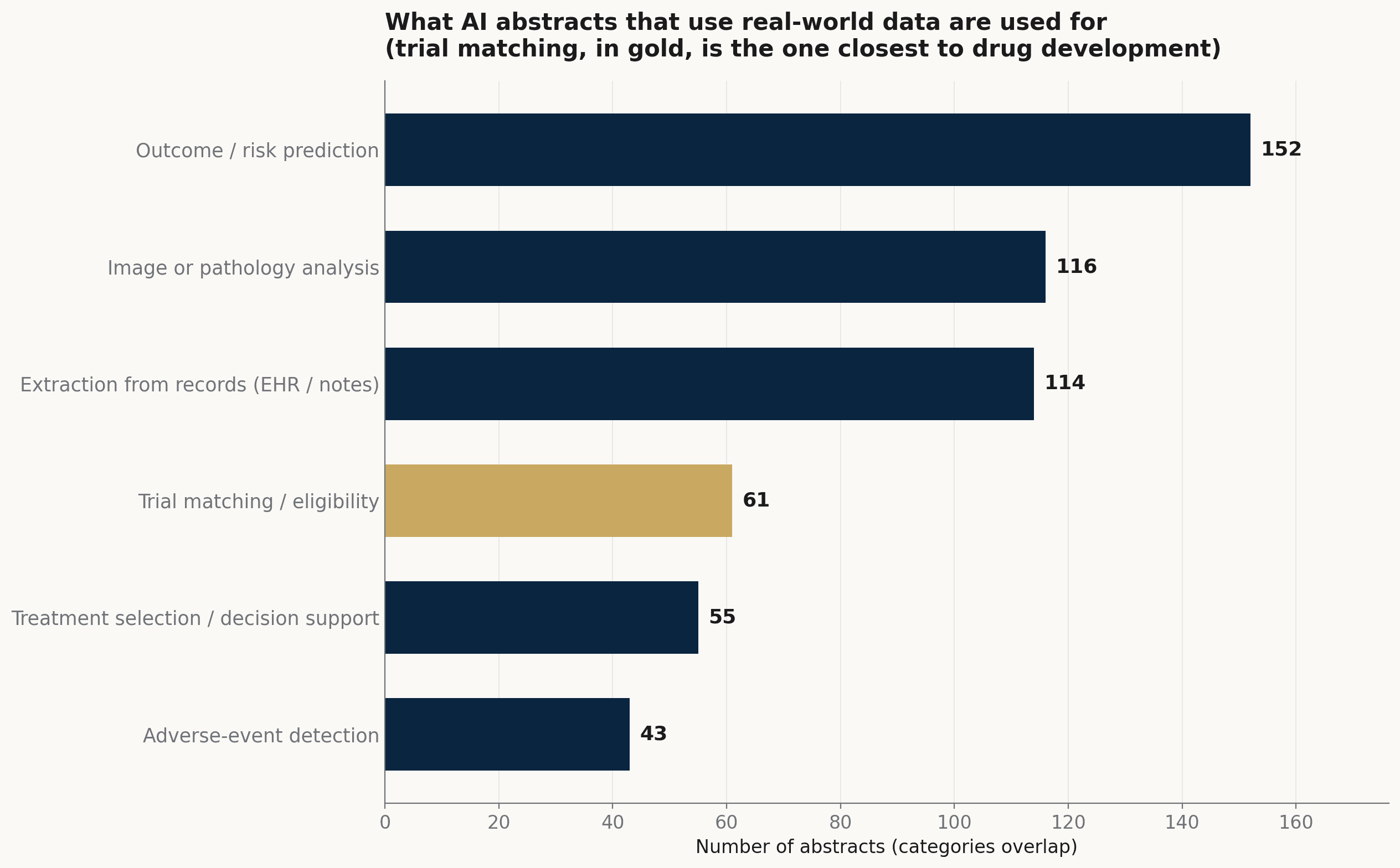
取用真實世界資料的 AI 摘要被用來做什麼。預測、影像與紀錄擷取是最大的幾件差事;試驗配對則是最貼近試驗如何被建立的一塊。類別可重疊。
資料來源:ASCO 2026 公開議程 · AAI 關鍵字分析(類別可重疊)
餵養這些任務的資料,愈來愈是真實世界、而非來自試驗:臨床紀錄、registry 與理賠資料出現在全議程的 2,157 篇(27%)。當一篇 AI 摘要同時取用真實世界資料,這些紀錄就是模型所讀、所預測、所篩選的原料——不過共用一個關鍵字標籤,只是兩者實際接得多緊的粗略代理。約三分之一的 AI 摘要(1,039 篇中的 339 篇,33%)也提到外部或前瞻性驗證的步驟,這大致反映出有多少把工具拿到建構資料以外去測試。
/ trial-matching /
試驗配對:AI 最貼近試驗如何被建立的一塊
在這些實務差事裡,試驗配對最貼近藥物開發。它是用 AI 來判斷哪些病人符合哪些試驗的資格,並從一間診所自己的病人群裡主動撈出候選者,而不是等他們被轉介進來。它也是議程中方法學描述最詳細的一塊,值得把整條管線走一遍。
這類工具共用一套大致相同的概念架構,通常三步。第一步,把試驗的適格條件——為人類讀者寫成散文的 inclusion 與 exclusion——解析成可運算的規則:像「measurable disease、ECOG 0–1、無 prior anti–PD-1、EGFR exon 19 deletion」這樣一句(僅為示意),被拆成一組結構化、可查詢的條件(忠實的編碼還得釐清是哪一版 RECIST、哪一種 assay、第幾線治療)。第二步,從紀錄組出病人 profile——結構化欄位,再加上非結構化的病摘、病理與基因報告。其中一部分是用自然語言處理自動擷取;一部分仍是由人用病歷自由文字搜尋工具(如 NCI 支援的 EMERSE)把相關段落撈出來。第三步,一個配對引擎拿兩者互比——傳統上是在結構化欄位上跑規則邏輯,再疊上 NLP 與 ontology 對映。有些較新的系統用大型語言模型逐條裁定條件、回傳附逐條理由的排序候選名單,但這是新興做法、還不是常態,而且其輸出是供人覆核,而非自主決定。
這些工具怎麼被測試,和它們怎麼運作一樣重要,而議程對此講得很明白。Abstract 1501 是最清楚的一例:在一間 community–academic 混合型癌症中心做的回溯性研究,把一套 AI 集中式篩選系統,拿來和它可能輔助的人工 pre-screening 相比,並由專家或人工裁定配對結果。它的 framing 很直接——收案不足,部分是因為 pre-screening 仰賴人工,而一套 AI 篩選「需要穩健的驗證才能促成信任與採用」。它的終點是與那份人工判斷在既有紀錄上的一致性;它說的是可行性與信任,而不是是否真的有更多病人被收進試驗。
真正難的,與其說是配對邏輯,不如說是背後的資料。條件常常取決於紀錄並未以結構化形式持有的事實——一個還沒被開立的分子檢測、一段埋在敘事裡的前線治療史、一個「28 天內」的時間窗、一條只存在於自由文字裡的「無活動性自體免疫疾病」排除條件。否定語、時序與治療線數的排序、缺漏或尚未做的檢測,以及各中心不一的病歷書寫習慣,都是自動化適格判斷常出錯的地方——在一間中心驗證過的工具,未必能搬到下一間。而議程目前還沒能呈現這些工具能在規模上提高收案的前瞻性證據;多數報告,包括 1501,都停在可行性與一致性。方向已定,結果數據還在前頭。
/ new-subtrack /
議程把這類工作放在哪,以及前緣技術
2026 年,議程新增一個次分類,名為 Clinical Informatics / Artificial Intelligence / Data Science,把先前分散在各疾病與方法軌道上的運算與資料工作收攏起來。它收了 83 篇摘要。
在更廣的議程裡,最新的技術仍是薄薄一層。大型語言模型或具名的 GPT 系統出現在 115 篇,foundation model 在 22 篇,digital twin 在 5 篇。這些是名義上的前緣;在數量上,對照 8,025 篇發表,仍然很小。
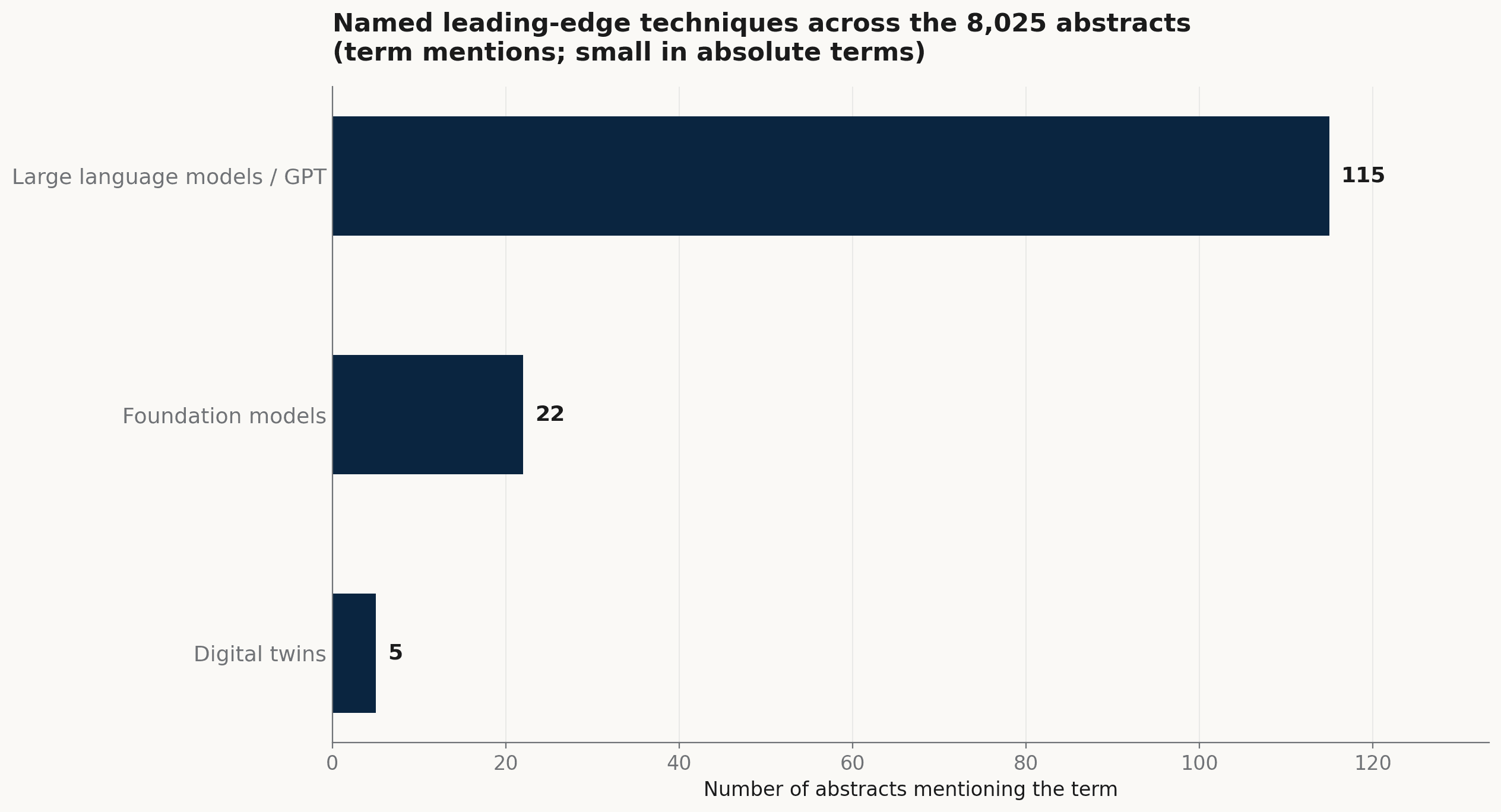
8,025 篇摘要中,具名的前緣技術。大型語言模型以提及次數領先;foundation model 與 digital twin 在絕對數量上仍小。
資料來源:ASCO 2026 公開議程 · AAI 關鍵字分析(術語提及)
新增一個次分類是一個前瞻訊號。當議程委員會判斷某一類工作已成形到足以單獨追蹤時,才會把它收進同一個標題之下——這通常標示出組織者預期之後會有更多。它本身對科學說得不多;它說的是議程在哪裡騰出了位置。
/ takeaway /
方向,以及我們的位置
從議程可讀出兩個方向,都謹慎看待。其一,AI 正從研究的「主題」,轉向完成任務的「手段」:多數 AI 摘要現在報告的是一件被完成的差事——做了一個預測、讀了一份紀錄、配對了一個病人——而不是為了方法本身而引入一個方法。
其二,最貼近操作的那些任務——試驗配對、適格篩選、site 選擇——是 AI 最可能直接接上試驗運作方式的地方。那裡的證據目前還停在可行性層級,而非前瞻性結果,所以這是一個值得觀察的方向,而非已成定論的結果。
這正是 Apex AI Institute 藥物開發這條線工作的地方。Pillar 1 為早期腫瘤學試驗開發並評估 AI 方法——site 與 investigator 選擇、試驗配對,以及 biomarker 分析。ASCO 議程正忙於同樣這些任務,是背景脈絡,而不是對任何單一工具(包括我們自己的)的驗證。我們會在後續的 briefing 裡報告我們自己的系統,並明白交代它們的驗證狀態,使用與本篇相同的模板。