ASCO Annual Meeting 2026 · Conference briefings
AI at ASCO 2026: From Topic to Tool
Of 8,025 presentations in the ASCO 2026 program, 220 carry the Artificial Intelligence tag — the largest single subtrack. Most of that AI is not a new model. It is a tool put to a concrete job: predicting from records, reading images, structuring notes, and matching patients to trials.

/ scale /
How much AI, and where it sits in the program
Begin with the count, before reading any single abstract. Of the 8,025 presentations indexed in the public ASCO 2026 program, 220 carry the "Artificial Intelligence" subtrack tag — the largest single subtrack, ahead of any individual disease-site or drug-class subtrack. Counted more broadly, 1,039 abstracts (13%) mention AI methods somewhere in their text. The figure reflects how ASCO labels abstracts, not a head-to-head count of every method.
Of the 220 AI-subtrack abstracts, 136 (62%) are designated "Publication Only" — accepted into the online proceedings rather than given a poster or an oral slot. Across the wider set of 1,039, the split is similar: 527 (51%) are Publication Only. Much of the AI in the program arrives as written proceedings, read online rather than presented from the floor.
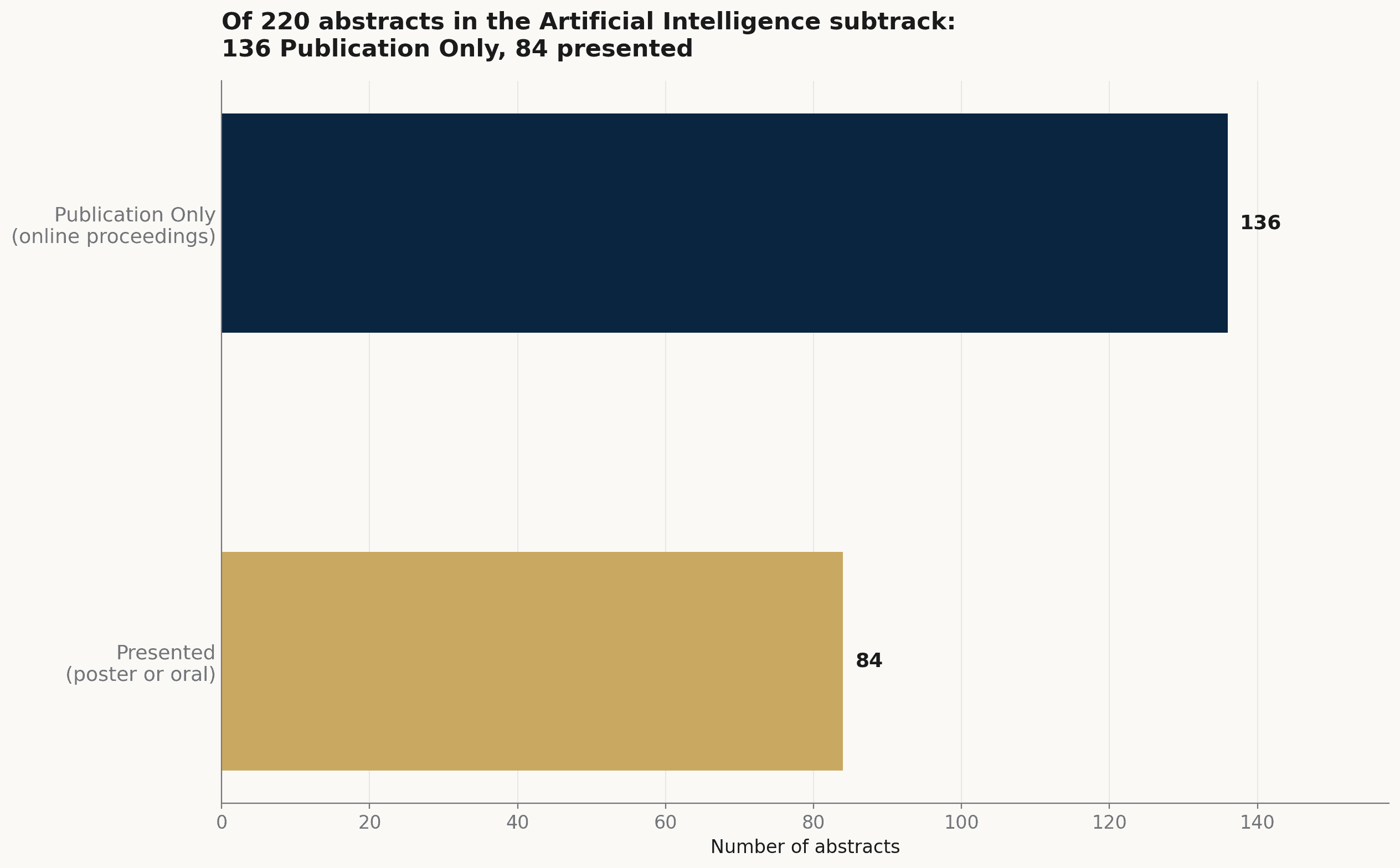
The 220 abstracts in the Artificial Intelligence subtrack, split by how they entered the program: 136 as Publication Only, 84 with a poster or oral presentation.
Source: ASCO 2026 public program · AAI analysis
The share is the point to hold. A method that fills the single largest subtrack, and that mostly arrives as accepted proceedings rather than as a podium talk, reads less like a headline topic and more like what may now be a routine part of how the work is reported.
/ uses /
What the AI is used for
Read by task, the AI in the program clusters into a small number of practical jobs rather than one dominant application. (An abstract can fall into more than one, so the groups overlap.)
Among the AI abstracts that draw on real-world data, the largest group builds outcome and risk prediction from routine records (152). Reading images and pathology is close behind (116), as is turning unstructured records — notes, charts, electronic health records — into structured fields (114). Trial matching and eligibility screening (61), treatment selection and decision support (55), and adverse-event detection (43) follow. One abstract applied a large language model to flag immune-related adverse events directly from the health record (Abstract 12133); another embedded a natural-language-processing chatbot in a phase II trial to triage patient-reported symptoms by a risk algorithm (Abstract 12132).
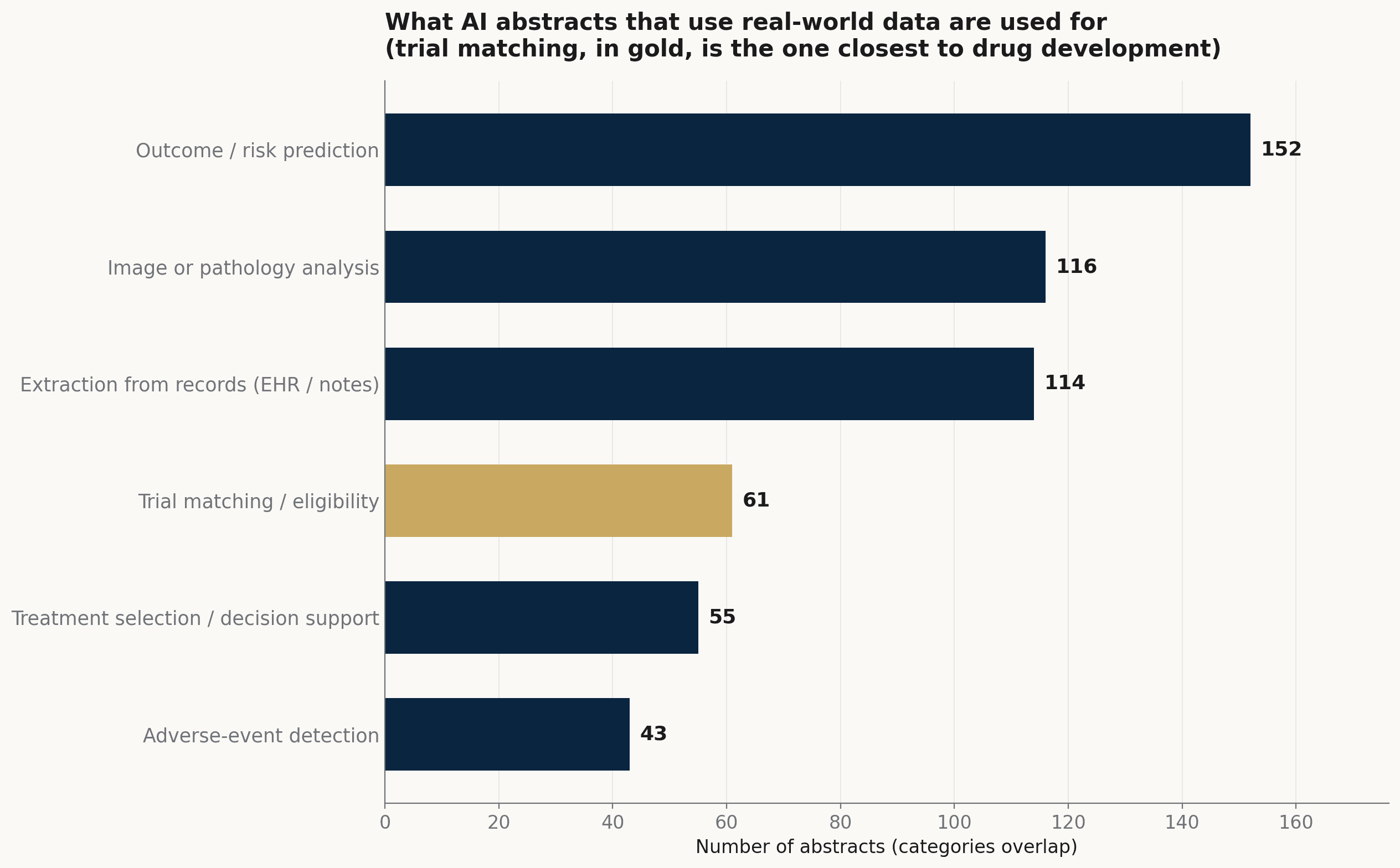
What the AI abstracts that use real-world data are used for. Prediction, imaging, and record extraction are the largest jobs; trial matching is the one closest to how trials are built. Categories overlap.
Source: ASCO 2026 public program · AAI keyword analysis (categories overlap)
The data feeding these tasks is increasingly real-world rather than trial-derived: clinical records, registries, and claims appear in 2,157 abstracts (27%) across the program. When an AI abstract also draws on real-world data, those records are the raw material the model reads, predicts from, or screens — though a shared keyword tag is a loose proxy for how tightly the two are actually wired together. Roughly a third of AI abstracts (339 of 1,039, 33%) also mention an external or prospective validation step, which gives a rough sense of how many test the tool beyond the data it was built on.
/ trial-matching /
Trial matching: AI closest to how trials get built
Of the practical jobs, trial matching sits closest to drug development. It is the use of AI to decide which patients are eligible for which trials, and to surface candidates from a clinic's own population rather than waiting for them to be referred. It is also the task the program describes in the most methodological detail, so it is worth following the pipeline end to end.
These tools share a common conceptual architecture, usually three steps. First, the trial's eligibility criteria — inclusion and exclusion written in prose for human readers — are parsed into computable rules: an illustrative line such as "measurable disease, ECOG 0–1, no prior anti–PD-1, EGFR exon 19 deletion" becomes a set of structured, queryable conditions (a faithful encoding also has to pin down which RECIST version, which assay, and which line of therapy). Second, a patient profile is assembled from the record — structured fields plus the unstructured notes, pathology, and genomic reports. Some of that is automated extraction with natural-language processing; some is still a person using a free-text record-search tool, such as the NCI-supported EMERSE, to surface the relevant passages. Third, a matching engine tests one against the other — historically rule-based logic over structured fields, with NLP and ontology mapping layered on. Some newer systems use a large language model to adjudicate each criterion and return a ranked candidate list with a per-criterion rationale, but that is an emerging approach, not the norm, and the output is meant for human review rather than an autonomous decision.
How these tools are tested matters as much as how they work, and the program is explicit about it. Abstract 1501 is the clearest case: a retrospective study at a community–academic hybrid cancer center comparing an AI centralized-screening system with the manual pre-screening it might support, with expert or manual adjudication of the matches. Its framing is pointed — under-enrollment persists in part because pre-screening is manual, and an AI screen "requires robust validation to facilitate trust and adoption." The endpoint is concordance with that human judgment on records already collected; it speaks to feasibility and trust, not to whether more patients actually enrolled.
What makes this hard is less the matching logic than the data behind it. Criteria often turn on facts the record does not hold in structured form — a molecular test not yet ordered, a prior line of therapy buried in a narrative, a "within 28 days" window, a "no active autoimmune disease" exclusion that lives only in free text. Negation, timing and line-of-therapy sequencing, missing or not-yet-performed tests, and documentation that varies by site are among the common places automated eligibility breaks — and a tool validated at one center need not generalize to the next. The program does not yet show prospective evidence that these tools raise enrollment at scale; most reports, 1501 included, stop at feasibility and concordance. The direction is set; the outcome data is still ahead.
/ new-subtrack /
Where the program files this work, and the leading edge
For 2026 the program added a subtrack named Clinical Informatics / Artificial Intelligence / Data Science, gathering computational and data work that had been spread across disease and methods tracks. It carried 83 abstracts.
The newest techniques inside the wider program remain a thin layer. Large language models or named GPT systems appear in 115 abstracts, foundation models in 22, and digital twins in 5. These are the leading edge by name; in volume they are still small against 8,025 presentations.
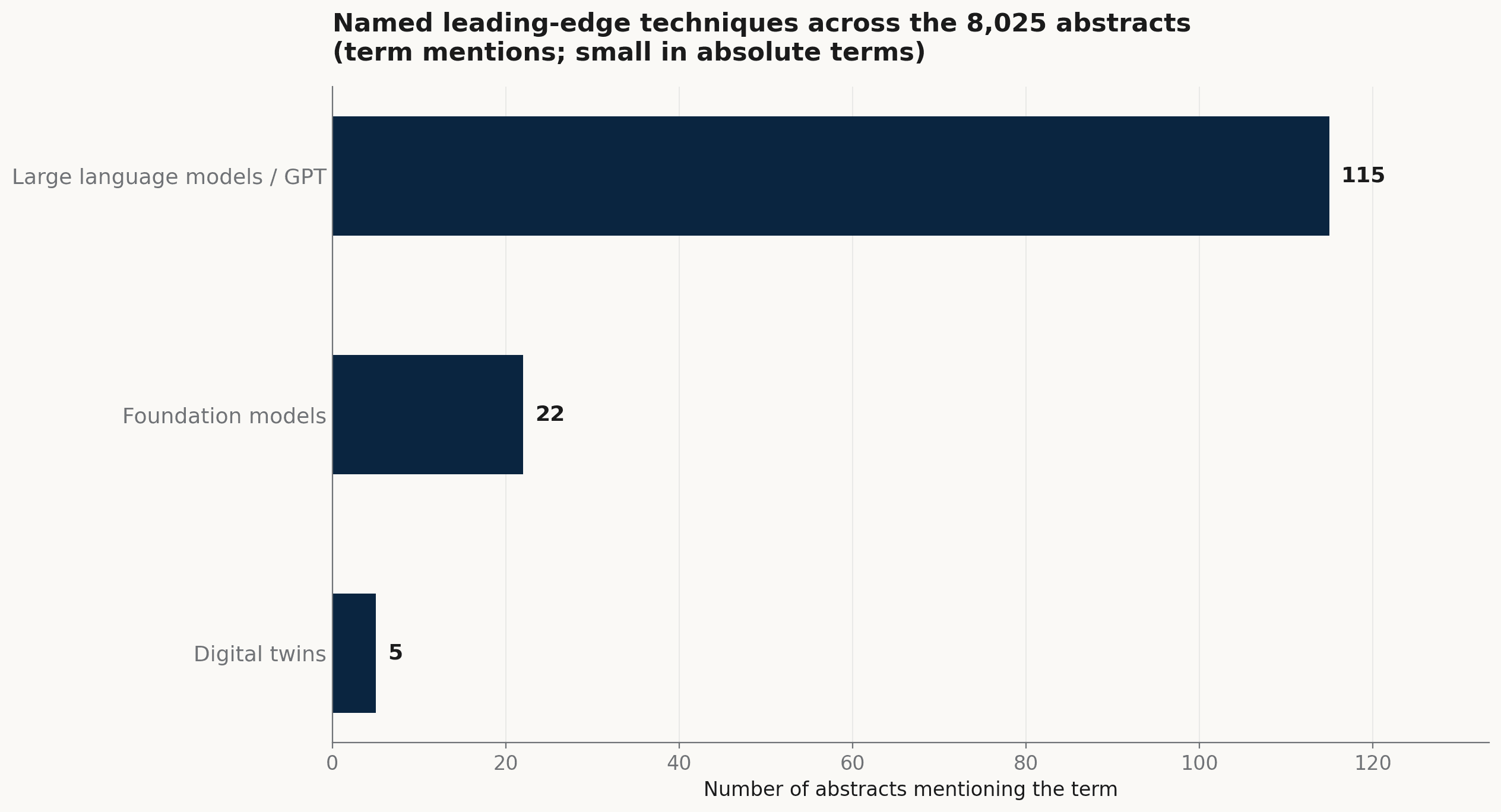
Named leading-edge techniques across the 8,025 abstracts. Large language models lead by mention count; foundation models and digital twins remain small in absolute terms.
Source: ASCO 2026 public program · AAI keyword analysis (term mentions)
A new subtrack is a forward signal. A program committee groups a body of work under one heading when it judges the work coherent enough to track on its own — which usually marks where the organizers expect more to come. On its own it says little about the science; it says where the program is making room.
/ takeaway /
The direction, and where we work
Two readings carry from the program, both held lightly. First, AI is shifting from the subject of a study toward the means of doing a task: most AI abstracts now report a job done — a prediction made, a record read, a patient matched — rather than a method introduced for its own sake.
Second, the tasks closest to operations — trial matching, eligibility screening, site selection — are where AI may most directly interface with how trials are run. The evidence there is still feasibility-level rather than prospective outcome, so this is a direction to watch rather than a settled result.
This is where Apex AI Institute's drug-development line works. Pillar 1 develops and evaluates AI methods for early oncology trials — site and investigator selection, trial matching, and biomarker analysis. That the ASCO program is busy in the same tasks is context, not a validation of any one tool, ours included. We will report our own systems in the briefings to come, with their validation status stated plainly, on the template that carries this one.